Unlike internet startups, most large organizations started with multiple monolithic silos. As the organizations grew the need for connecting these silos increased. This led to the birth of integration patterns. There are four basic integration patterns widely used in enterprise:
- File transfers
- Shared database
- Remote Procedure Calls
- Messaging / Queueing
Our large monoliths started interacting with other monoliths. As languages & tools evolved, people building new monolith with different languages and tools. This gave birth to a polyglot eco-system within the context of monolithic applications. These patterns integrated systems in a decoupled manner.
All the above-mentioned patterns are universal patterns and have specific property. Let’s look at them briefly before diving into the main topic.
File transfers are good for batch processing. Data are dumped into files and sent to other application(s) at a specific time using some file transfer protocol. These application needs to agree to a format. It is not always necessary to send the file to another system. Say both the applications are running on same host or share the same file System or network file system, then only thing you need is a bit of synchronization. The file being written by the producing system should not be picked up for reading by the consuming system and if multiple files are being written the consumer needs to ensure that they are consumed in order.
Shared database lets two application use the database at that same time. This makes the most recent data available at real-time. This sounds simple but comes with lot of friction. Due to shared nature of the DB, it will be difficult to make changes to the DB. What if the column name you are changing or the column you are dropping is being used by another application(s). Also, there will be questions around ownership. What happens when application B want to change the data owned by application A.
Remote Procedure Calls is not limited to true RPC (that uses stubs), but it can also be a web service call. This is an area where we are seeing a lot of evolution. We have seen RPC, RMI, CORBA, SOAP, REST and recently gRPCs. Also, they lead to many architectural patterns like SOA, microservices, etc. All these techniques helped us build distributed applications that interacts with each other. This pattern has support from a lot of mature frameworks. However, there are problems: They are not good with asynchronous communications. They create a tight system coupling due to service availability and location knowledge.
Messaging is the technique of sending data over a message queue. The technique has given birth to event driven architectures. They are very good for asynchronous communication. They are great for decoupling systems and are highly scalable. In the space of messaging Kafka has taken the world by a storm and helped us come up with many new even driven architectures.
Messaging, for Integration
Message Queues are very useful technology in enterprise world. Because of its ability to decouple systems they are favorites among enterprise architects. Additionally, they are easy to scale and are very reliable. Because of their usefulness many implementations of messaging technology are available and are being used in the world of enterprise application. This doesn’t mean we should abandon all other patterns and only use messaging. The other patterns can be effective too and it all depends on your use case and trade-offs.
File Queues
To start with let’s look at file queue. If two separate processes on the same host wants to exchange messages, we can make use of files. The producer process can write messages into a file say all through the day and at certain time it closes the file and will start writing into a new file. The consumer process just reads from the file once the producer is done with it. Maybe once the producer is done writing into the file, it moves it to another folder or change its permission from write only to read only. The consumer can poll for the presence of file at its input folder or checks if there is any file with read permission or may start at a predetermined time (i.e. it is scheduled) and looks for the file to consume.

This is very similar to our file transfer pattern, where the applications are far apart and the producer upon closing the file, transfer it to its consumer’s host. By creating multiple copies of the file, we can give it to multiple consumers. This is how many data providers share their data. Like Bloomberg sending 3 files with financial data during different predetermined times of the day. This is based on market close time of different region.
Now what if we want data bit more real time. Say a consumer gets a big file every 6 hours and it takes 2 hours to process the data. After processing the consumer sits idle for 4 hours. Also during this time there can be changes happening at producer which are of interest to the consumer but it has to wait for the next feed. The consumer doesn’t want to wait 6 hours for the next file to arrive. It would be better if consumer can get smaller files many times during the day; say every 15 minutes. This is better for consumer. It doesn’t need to wait for the next file after processing a big batch of data. It is easer to process smaller batches than processing a big file. Also the data is getting sync much faster and is less stale in case the consumer is loading the data in a database.

In the above diagram you can see that the producer is producing smaller files and the consumer is reading them. This is a file queue. The producer can use various strategies for producing files:
- Create a new file every 15 minutes
- Switch to a new file after writing 100 message
- New file every 100 message but switch to a new file if there are no message to write for some X seconds
With a slow consumer you will see the queue size (i.e., number of files to be processed) increasing. With same production and consumption speed, we will see a stable size of file queue.
When files are getting generated every 15 minutes, then one can think of sending these files over to another system via sFTP, FTP, etc. But if the files are getting generated more frequently, sharing them with producer using some file transfer protocol is not maintainable. These high-throughput file queues can be considered if the producer and consumer are on the same host or shares a common network drive (NFS/NAS).
Message Queues
What can we do to have real-time communication or as real-time as possible. One for solution would be to establish TCP/IP connection between the two applications and send messages through it. It is good but needs both the applications to be available. This is not good as it is adding a dependency. The other solution would be to use Message Queues (MQ). Producer pushes messages over an MQ. Consumers remove messages from the queue and processes them. There can be more than one producers pushing messages to one MQ. You can have multiple consumer consuming from a queue but two or more consumer cannot get same message. Meaning MQs are point-to-point and does not support pub/sub where multiple consumers get to process the same message.

Messages are pushed asynchronously. It is best suited for fire and forget type of messages. However one can implement request response by using two queue, request queue and response queue. One can make use of correlation id of message to identify the response to a request sent over request queue.
MQs ensures better decoupling of producers and consumers. A message will be available in queue till a consumer gets and commits the message. Due to this, a slow consumer can lead to accumulation of queue depth over time. MQs are configured to have limited capacity when it comes to message retention in queue. So, if the consumer goes down and producer is actively pushing messages into the queue, the queue will get full. This can lead to message loss.
MQs can be easily monitored. There are administration commands that can give us the status of a queue. With the help of these commands the applications can save guard themselves from message loss.
- Creation of a monitoring logic such that, if depth of a queue reaches a certain threshold value (say 95%) we stop the producer and generate alert
- There is another nifty way, what if the consumer implement a thread that reads messages from MQ and store them in files on disk, thus implement MQ to file queue. And, let the other thread(s) consume the messages from file queue. Instead of threads we can make use of two different processes at consumer end to do the same.

One should implement both the techniques to get the best result. The second technique helps when for some reason the consumer starts taking longer to process a message. A slow consumer won’t block the queue as messages are consistently getting remove from the message queue. In the worse case your file system can get full and choke the consuming application. But the process will be slow and can give you enough time to react depending on available space on file system.
So in short with MQs we were not able to build fully decoupled applications, as we need to monitor the MQs and be aware of slow consumers even if the producer is not aware of the consumer.
Kafka
I guess Kafka saw these problems of using message queue and created a new messaging variant. It allowed the producers to push events (synonymous to messages) to a topic (synonymous to message queue). The events are stored in files; similar to file queue (described above). Thus these events are organized and durably stored in topics. Kafka also provides various guarantees such as the ability to process events exactly once (similar to message queue) by a consumer.
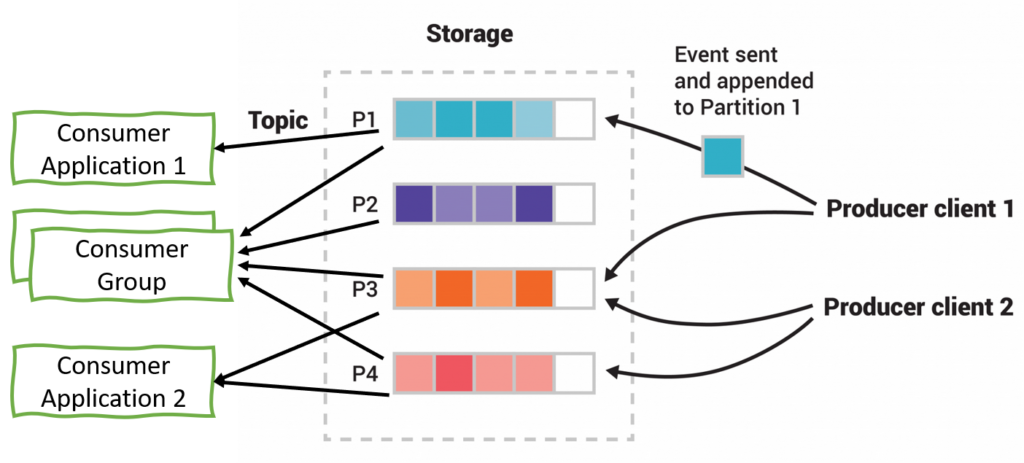
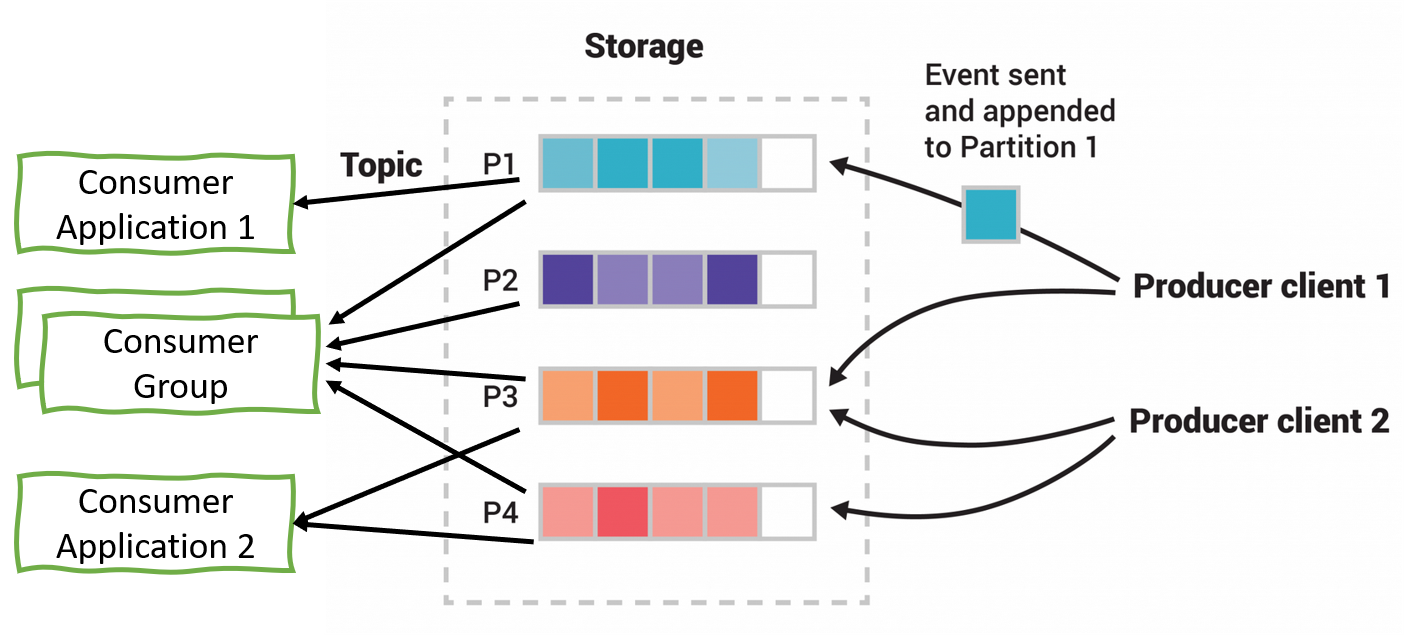
Kafka supports partitioning of topics and these partitions are served by different brokers. This distributed placement of data increases scalability. The producer client controls which partition a message should be published to. This can be done at random or with the help of some semantic partitioning function. To give an example from the messaging world, say a client instead of publishing data to one MQ decides to publish data to 4 MQs based on modulus split (i.e. if the message key’s % 4 is 0 then send message to 1st MQ, if 1 then to 2nd MQ and so on) or say if new data is getting created we push to a new entity queue and for updates we push them to update queues and there can be separate consumers consuming from them.
Unlike message queue, Kafka retains these messages and removes them after certain retention period. Due to this change, one or more consumer can read the data from a topic independently at the same time. Kafka just need to keep track of the indexes from which each consumer is consuming the messages. This is how it support pub/sub.
Kafka is very flexible with the way one wants to setup the consumers. As shown in the image above, you can configured a consumer to read from one partitions or a consumer to read from multiple consumers or create a consumer group.
A consumer group is a set of consumers which cooperate to consume data from some topics. The partitions of all the topics are divided among the consumers in the group. As new group members arrive and old members leave, the partitions are re-assigned so that each member receives a proportional share of the partitions. This is known as rebalancing the group.
Longer message retention by Kafka; this changes everything. It enabled some new usage pattern. In case something goes wrong within the retention period one can reset its index and reprocess. It’s like a replay function in the world of computing. These features of Kafka gave birth to multiple new architectural patterns, Even Driven Architecture (EDA), Event Sourcing, etc.
As you can see Kafka has solved many of the messaging problems, and at the same time it is highly scalable and resilient. It has allowed consumer & producer to be more decoupled than it’s predecessors.
Conclusion
Over the years queueing patterns has came a long way, much has changed in the underlying technology. Embracing MQs or Kafka based on your need can help you build decoupled & resilient systems. At the same time Kafka is becoming the de facto choice for cloud native applications, because of its many advantages over traditional message queues.