
Caching is a technique that veteran software engineers has been using for many years now to improve performance. We all know about it to some extent. Currently there are multiple libraries & softwares available that can just be included and voilà!! We have a cache in our software. Caching is extremely powerful mechanism with the potential to reduce DB hits or reduce going to backend services; thereby improving application performance. In today’s world when single application servers are no able to meet the performance & scalability requirements and are being replaced by microservices or microservice based architectures, caching is playing a more critical role. This is the primary motivation for this piece.
Caching Topologies
Single In-Memory Cache:
This is one of the most simpliest form of cache. The general concept is once you load the data that needs to be cached from DB, you store it in memory. From then on if you need this data again you look into the cache first, if its present use it from there without fetching it from DB. As caches are in-memory, they can hold a finite number of elements. There are different strategies to decide which item in the cache should be remove to make place for a new item in the cache. One of the strategy can be Least Recently Used (LRU).
These caches can be of 2 types based on how the data is stored and acessed from the cache:
- IMDG – In-Memory Data Grid: uses map structure i.e. has key value pair
- IMDB – In-Memory DataBase: allows SQL like queries
It is also important to understand the operations that can be done on a cache:
- Read-Through: If not in cache, get it from DB and add to cache
- Write-Through: Adding a new item to cache will write to DB and update the cache synchronously.
- Write-Behind: Adding a new item to cache will write to cache and return. It will asynchronously update the database.
Distributed (client/server) cache:
Here we will have a cache server or service. The application will act like a client for the cache server. The application will not do DB hits and no data is stored in client. Below picture shows that multiple client applications are using the same caching server. Usually a proprietary protocol is used for client/server communication. Can be implemented using TCP/IP or a REST service.
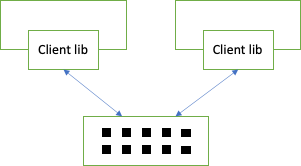
These caches are good for session management.
Replicated (in-process) cache:
Below diagram shows replicated cache, where every one has same data. This cache is not in client server mode.
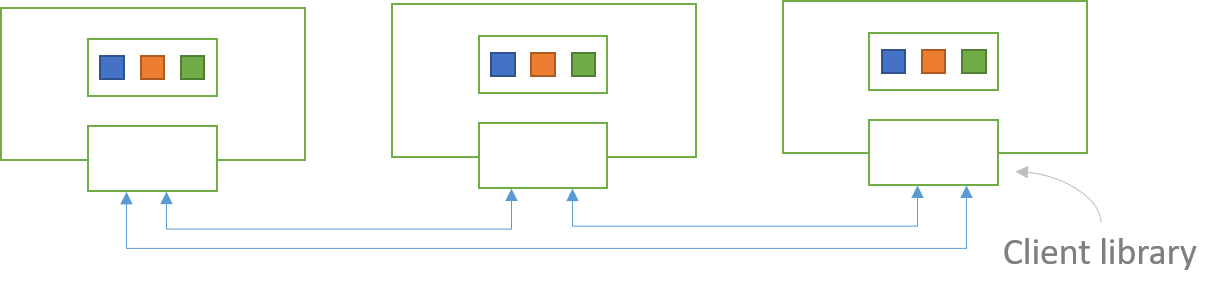
- Here two different data insertion strategies can be used:
- Synchronous put: Wait for all other cache to get updated
- Asynchronous put: Don’t wait for other cache to get updated
In replicated (in-process) cache, after one of the server goes down it gets back the full cache once its back.
- Java, C++ & C implementation of this caching mechanism are provided by:
- apache Ignite
- Hazelcast
Near-cache hybrid:
This is another variation where, required data is cached in the application. This is called front cache. This cache can use strategies like Most Recently Used (MRU) or Most Frequently Used (MFU) for maintaining data in the cache. Front Caches are not replicated, they can have different data. Below is how Front Caching works
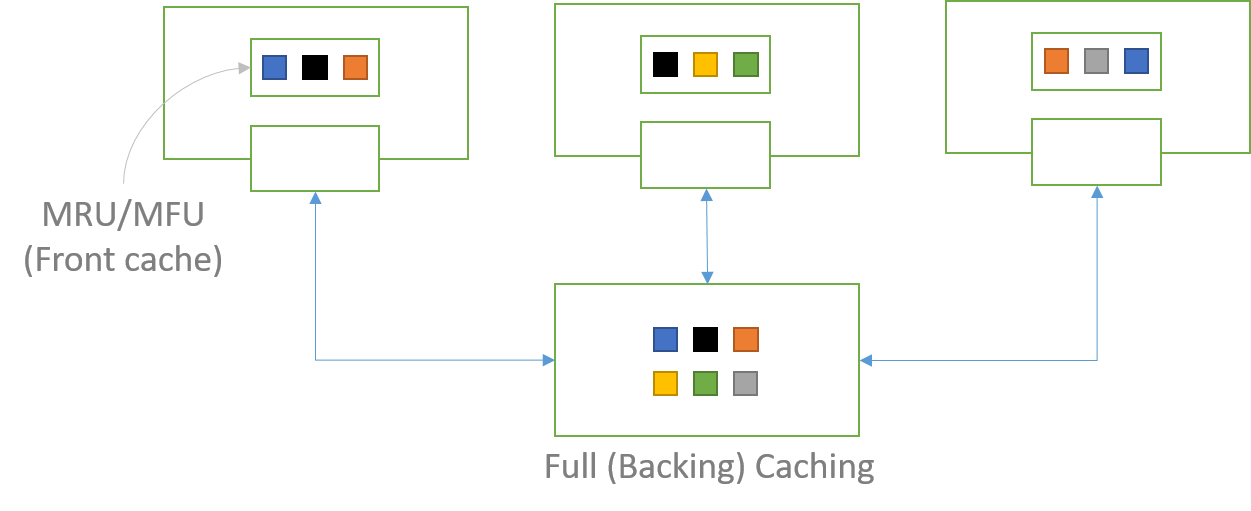
- If the data is not in my cache, then request from full cache. The full cache is also called Backing Cache.
- If data is not in full cache, it tries to get the data from DB and then send back the response and update the Backing cache. That is, it does a read-through.
- The data is in full cache, then it send back the response immediately.
This cache is slow and can lead to inconsistency.
Replicated Near Cache:
Once you understand the basic concept, you can think of multiple variations using the basic building blocks. This is one such variation. I am not giving its description but would like you to imagine; as a hint, there is no backing server in this implementation.
I don’t know of any off-the-shelf product that support this variation; but, I have seen this in a real application.
Replicated cache & data collisions:
Data collisions are an issue when using asynchronous data replication to keep the caches in sync in an active/active application network. Because there is a delay to replicate a data from from one cache to another when using asynchronous replication (a delay time which we call replication latency), there is the possibility that the data in cache are out of synch. Also two nearly simultaneous updates to same data can lead to loss of original update.
Collision rate = # of instances * ( (update rate)2/cache size ) * replication letancy
Possibility of errors in N time = Collision rate * N time
Off-the-shelf caches
- Apache Ignite
- Hazelcast
- Pivotal GemFire
- Oracle Coherence
i would like to see implementation details with example for one if possible
forgot to mention site seems pretty well organized and good content and topics
Thanks Sidd